Conceptual comparison of our method vs. contemporaries

Figure 1: Conceptual comparison between our proposed TCA vs. the contemporaries.
We propose TCA (Test-time Calibration via Attribute Alignment), a method that enhances confidence calibration in Vision-Language Models (VLMs) during zero-shot test-time prompt tuning. TCA extracts class-specific attributes using Large Language Models (LLMs) and incorporates them into prompts to preserve model calibration while improving classification accuracy.
Figure 1: Conceptual comparison between our proposed TCA vs. the contemporaries.
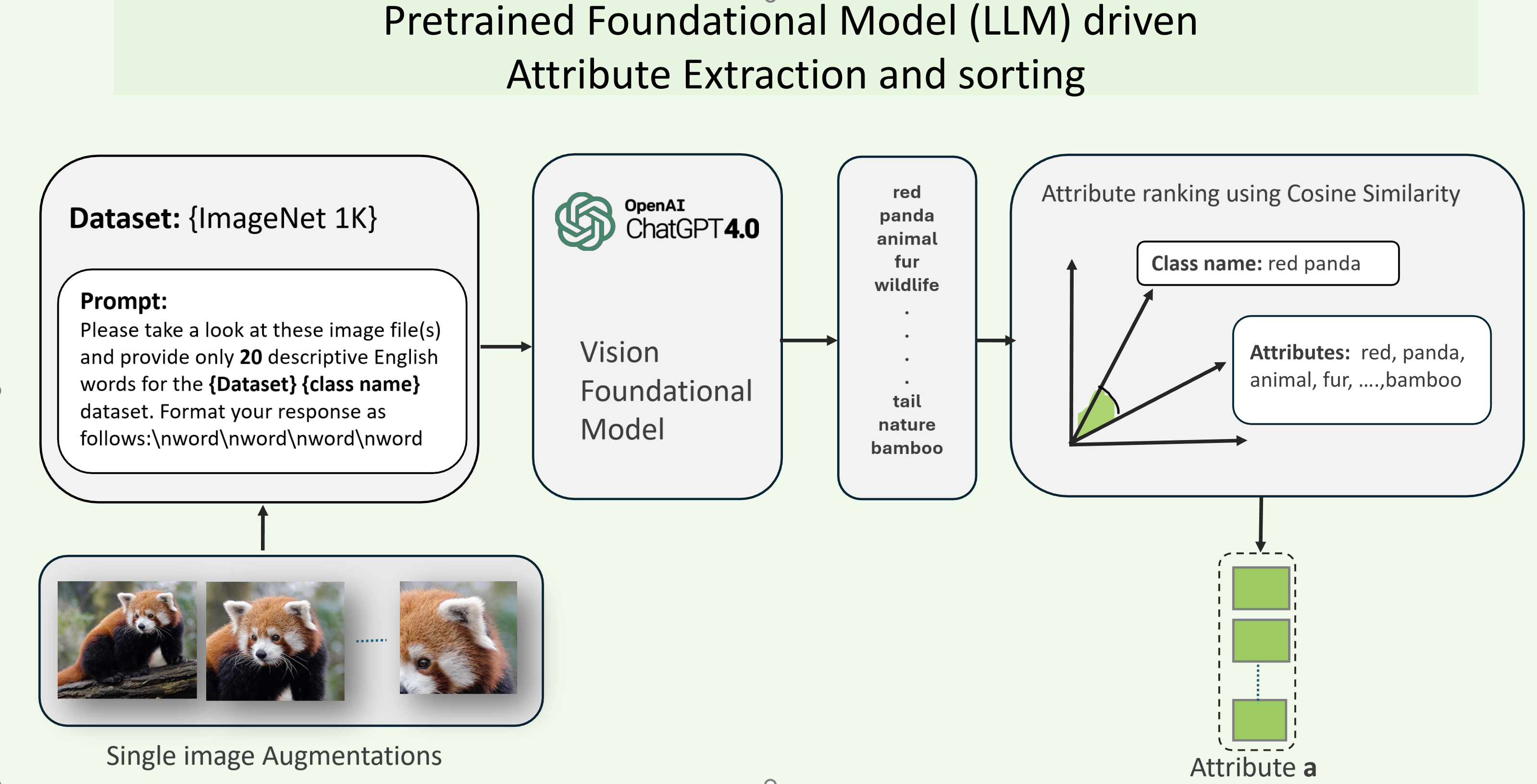
Figure 1: Illustration of class-specific attribute extraction using language prompts. LLMs generate attribute descriptors that are semantically aligned with the class name and visually discriminative. This enhances interpretability and paves the way for attribute-guided calibration.
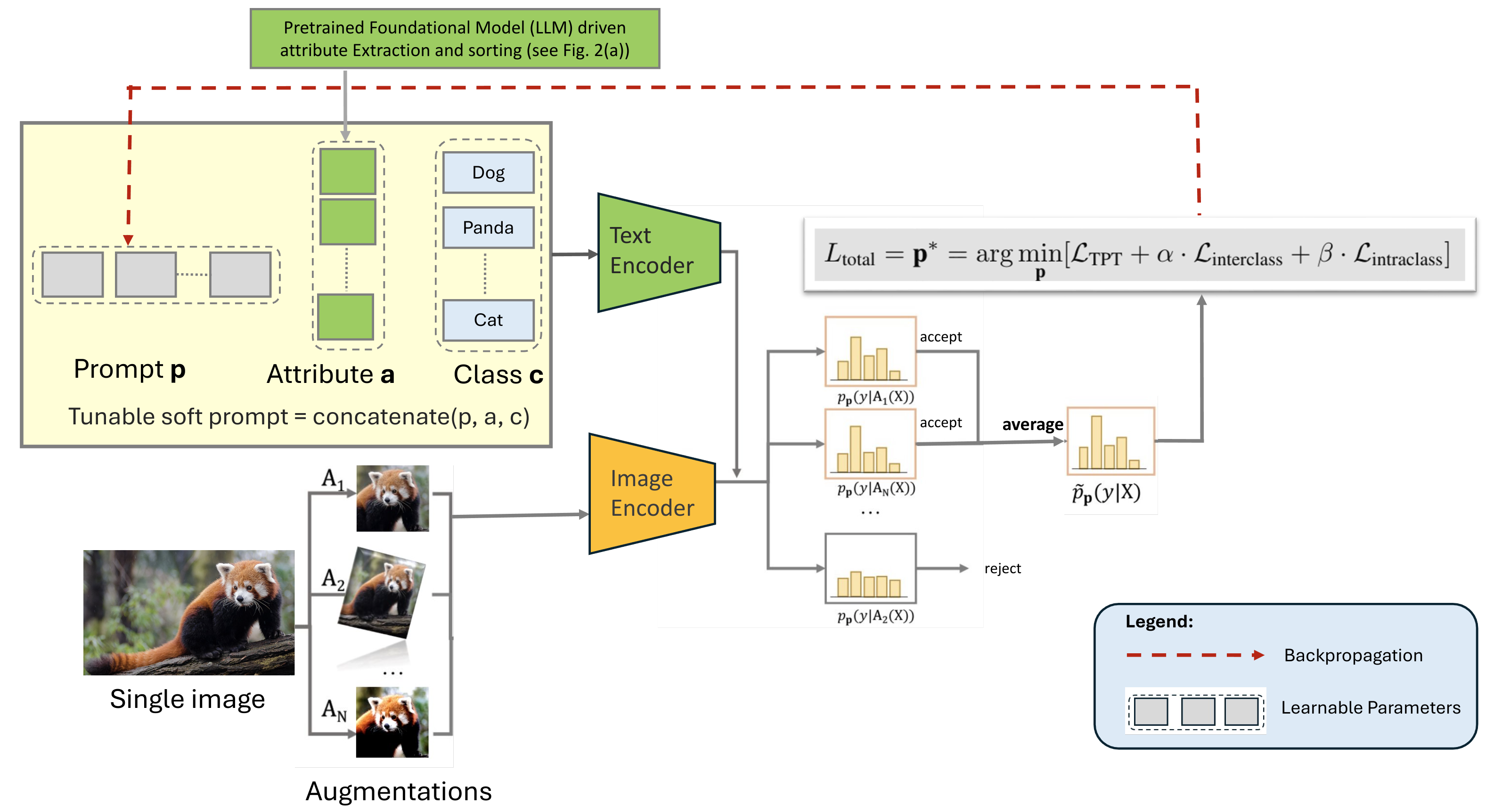
Figure 2: Overview of the Test-time Calibration via Attribute Alignment (TCA) framework. (Top) Extracted attributes from the previous illustration generate soft prompts used during inference. Calibration error is minimized by aligning predicted features with those induced by text-based attribute prompts via TCA loss. (Bottom) Final classification is guided by semantically enriched and calibrated textual representations.
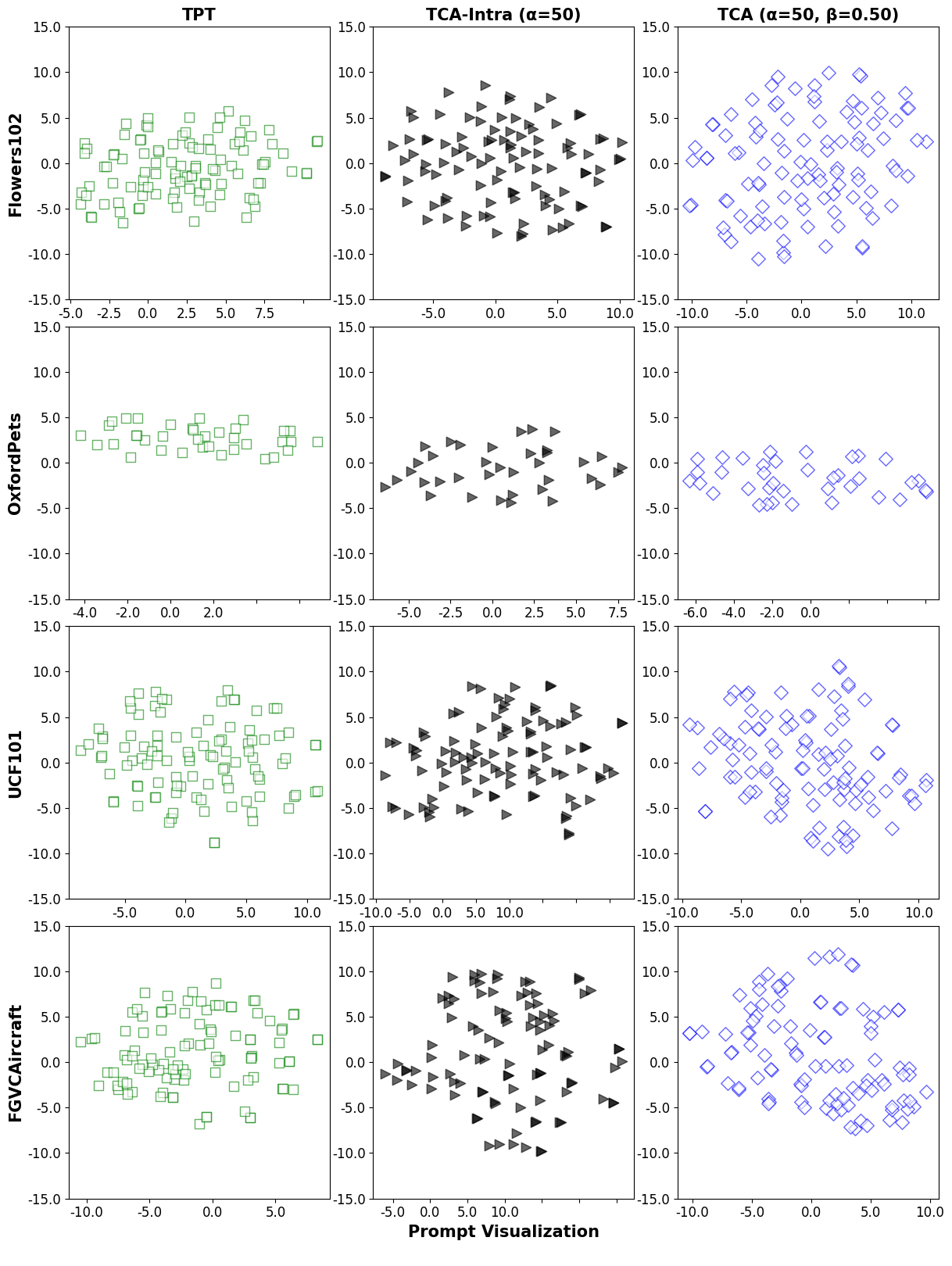
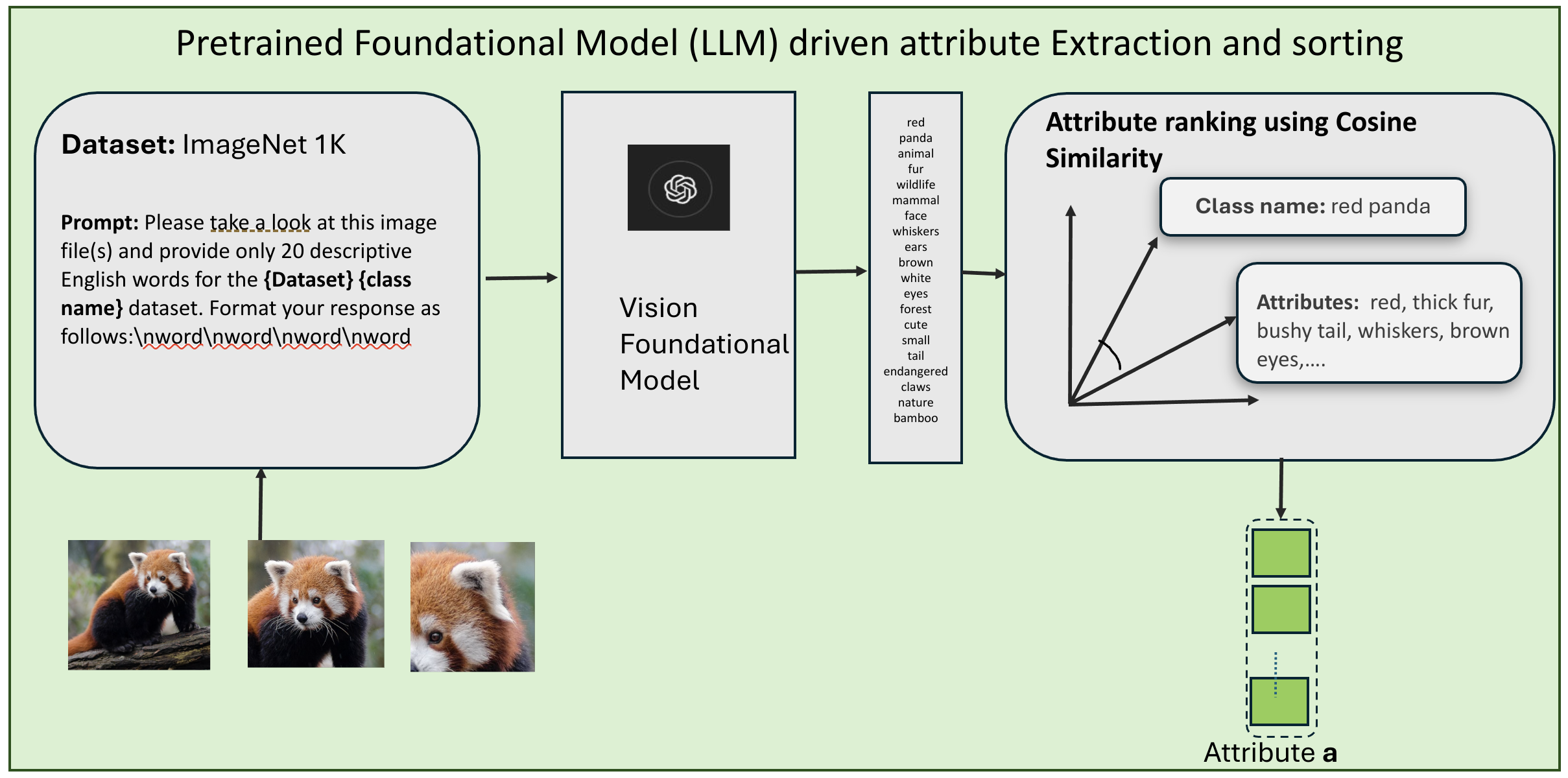
Figure 4: t-SNE plots of visual feature space before and after TCA. Post-calibration features show better separation and tighter clusters per class, illustrating how attribute alignment refines semantic structure in embedding space.
Table 1: Ablation study showing how the number of selected attributes affects calibration performance. Optimal ECE is achieved using 2 attributes, after which adding more leads to marginal degradation due to attribute dilution.
| Attributes | ECE (CLIP-RN50) | ECE (CLIP-ViT-B/16) |
|---|---|---|
| 0 | 25.7 | 19.9 |
| 1 | 20.3 | 12.1 |
| 2 | 5.59 | 4.05 |
| 3 | 7.34 | 4.48 |
Table 2: Accuracy and calibration (ECE) results across diverse fine-grained datasets. TCA improves ECE significantly while maintaining or improving classification accuracy, highlighting its utility in real-world recognition tasks.
| Dataset | Accuracy (%) | ECE (%) |
|---|---|---|
| Caltech101 | 93.26 | 3.09 |
| Flowers | 68.9 | 3.57 |
| Food101 | 84.23 | 1.91 |
| Aircraft | 25.38 | 3.36 |
| EuroSAT | 44.3 | 4.36 |
| UCF101 | 65 | 2.71 |
Table 3: Evaluation on ImageNet-based natural distribution shift datasets. TCA shows strong robustness and maintains calibrated predictions under distribution shifts (e.g., real, sketch, adversarial), outperforming uncalibrated CLIP.
| Dataset | Accuracy (%) | ECE (%) |
|---|---|---|
| ImageNet-A | 47.36 | 5.21 |
| ImageNet-V2 | 60.85 | 1.81 |
| ImageNet-R | 72.74 | 3.42 |
| ImageNet-S | 45.72 | 4.81 |
@inproceedings{hebbalaguppe2025tca,
title={Prompting without Panic: Attribute-aware, Zero-shot, Test-Time Calibration},
author={Hebbalaguppe, Ramya and Kandar, Tamoghno and Nagpal, Abhinav and Arora, Chetan},
booktitle={European Conference on Machine Learning (ECML)},
year={2025}
}